I spent the past ~4 weeks trying out all the new and fancy AI tools for software development.
Let’s get a few things out of the way:
- Learning how to use LLMs in a coding workflow is trivial. There is no learning curve. You can safely ignore them if they don’t fit your workflows at the moment.
- LLMs won’t magically make you deliver production-ready code
- If you can’t read the code and spot issues, they’re hard to use past the PoC stage
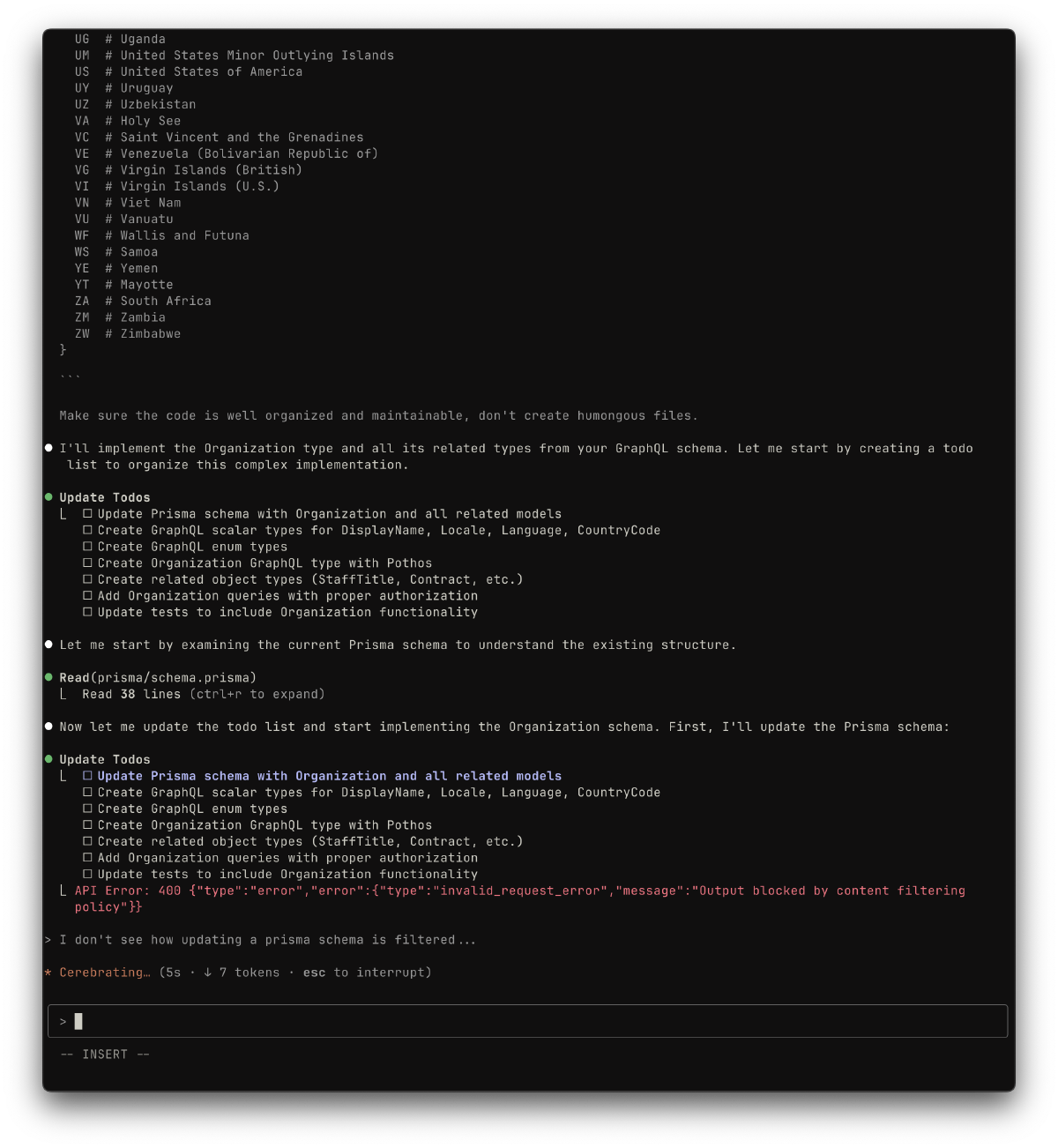
- They have terrible code organization skills, making them lose themselves on even medium-size codebases. They perform better on mature, well-written, well-documented codebases.
- They need you to know what you want to get the best results.
- By being particularly bad at anything outside of the most popular languages and frameworks, LLMs force you to pick a very mainstream stack if you want to be efficient.
- Using LLMs did make me a worse software developer, as I didn’t spend as much time reading docs and thinking as before. There’s a reason why most managers suck at writing code.
LLM-powered coding#
Since about a year ago, “agents” have become all the rage.
What you have to understand is that an agent is simply:
- Calling an LLM and giving it a list of (local) HTTP servers it can query with JSON payloads
- It outputting a query instead of a normal text response
- Waiting for the local server to respond
- Calling the LLM again with the same context as before + the tool’s response
That’s it. There’s no magic at work, no actual reflection, it’s just letting LLMs decide to answer by calling an API and then feeding them back the response and re-starting the process.
Furthermore, all “agents” use the same kind of tools:
- Code navigation (read files, grep, …)
- File edit
- Run shell command
- Mostly used to run linting, type checking, and tests
- Web search / URL fetch
- MCP servers
MCP servers all have roughly the same feature: offering access to existing data in a formatted way. For example, it could offer structured access to search in a Github repo, or a widget tree.
As LLMs are simply text completion tools, the better formatted the text is, the better results you get.
This makes MCPs very useful even though they’re just bridges to data that the LLMs could technically have access to through shell commands or web search.
Products#
Common issues#
All tools below have one glaring issue: stability.
As companies realize training 50 models a month and planning to amortize the cost by selling access to them won’t work because of new models and new hardware, they are backtracking hard on previous pricing promises.
You could be relying on a particular model just for your provider to make it “premium” the next day.
To compound this issue, new tools and models come out weekly, requiring you to update your setup to make the most of it. You need to change your prompts, update your MCPs, update LLMs project context, and so on and so forth as they all work slightly differently.
It’s very annoying for anyone trying to set up a stable, efficient workflow. You can’t fully rely on those tools as part of your development setup, because you don’t know how long they’ll stay available as-is, and they’re not deterministic.
Testing flow#
I used those tools both for my work and for personal projects, which includes:
- Working with Python
- Working with TypeScript
- Working with Rust
- Performing complex refactors, for example deep cross-project refactors in a monorepo
- Making a Flutter app
The tools mostly worked as advertised, except for one feature:
- Writing a Token Field in Flutter.
It’s not a particularly hard task, but it is on the rarer side of components and requires a lot of state management to get right.
Every single agentic LLM system failed at it. I tried it with Claude Opus 4.1 and GPT 5, which are supposed to be those new, super capable state of the art models, and they failed miserably.
The widget usually looked terrible, keyboard interactions were inconsistent, and the tests they wrote to validate behavior did not validate anything.
I think it’s a very good reminder: LLMs will always suck at writing code that has not be written millions of times before. As soon as you venture slightly offroad, they falter. That’s why you always see the same tired demos, with the same stock components.
Models#
There are 3 models that are widely used at the moment:
- Claude 4 Sonnet
- Or 4.1 Opus if you are a millionaire and want to pollute as much possible
- Gemini 2.5 Pro
- GPT 4.1 and 5
Claude 4 heavily outperforms the two others when it comes to agentic workflows.
Gemini 2.5 Pro might be good, but Google makes it incredibly painful to use for anything productive.
GPT 4.1 and 5 are mostly bad, but are very good at following strict guidelines. With a lot of tooling, you can get decent results out of it (see below).
Local models are also an option, but at the moment they really can’t compete with the huge closed models. Most small-medium models suck with tools, suck at complex features, and will be very slow.
I use local models for my private personal assistant, but for producing code they are unfortunately too underpowered at the moment.
Products#
Github Copilot#
10$/month, unlimited GPT4.1 calls, decent number of Claude 4 calls as extra, GPT 5 too as of 2025-08-08 (counts as premium requests).
Github Copilot is the OG, and it’s great value for the price. I was part of the alpha in 2021 and it was mind blowing at the time.
The biggest issues of Github Copilot is that it’s heavily tied to VSCode, as the Copilot Chat extension is VSCode-specific. This is very disappointing, as originally Github Copilot was working on nvim and Emacs. But since adding chat and agentic features, they completely gave up on supporting other IDEs.
Their agentic workflow extension is decent, but it’s starting to get messy as they pile and pile more features into it:
- It often fails to edit files
- Keyboard navigation is mostly bad and poorly integrated with the rest of VS Code
- With 3+ modes and 5+ models it’s a mess to get the right setup all the time without clicking everywhere
- Config changes every month with new VS Code releases, and half of the options don’t work
I would say Github Copilot is the most customizable, but it’s also its downfall.
To get it to do things right, you need to spend hours setting up poorly documented config files and buggy options.
It is getting better and at least they are not scared to iterate, but be ready that every month you’ll pretty much need to review all the features you are using.
Claude Code Pro#
20$/month, Claude 4 Sonnet “unlimited” with a limit resetting every 5h.
Claude Code is the cool kid on the block. Everyone uses Claude Code.
So I had to give it a try.
I liked the fact that it’s fully terminal-based, forcing people to make clean and reproducible tooling setup.
I disliked the fact that it’s fully terminal-based because the interface is very lackluster, the “Vim mode” is an insult to Vim users, and reading markdown in terminal just looks plain bad.
But it’s still just Claude 4 Sonnet. It is the same as Github Copilot’s for twice the price, but with higher usage limits if you plan to really only use Claude.
I also had more success fixing issues with Claude Code than with Github Copilot in some cases, despite them using the same model. It seems the prompts and tools are slightly more optimized for Claude 4.
Overall it’s decent, and I understand why it’s the market leader as it’s IDE-agnostic and gets the job done most of the time.
Gemini CLI and Jules#
Their pricing model is such a mess I won’t even try to make sense of it.
I have their Pro plan thanks to my participation in the Jules beta.
Gemini 2.5 Pro looks to be a decent model, but Google is fucking up everything so badly that it’s hard to evaluate it:
- Jules is a catastrophe and it has not once landed a proper feature in neither Python nor Flutter repos, even with heavy configuration and effort on my side
- Gemini Code is supposed to be free for 1000 requests, except you hit the limits in 10 minutes. And for some reason, it’s not part of the “AI Pro” plan
I even tried to access the models through their API, but it’s extremely buggy and slow.
The model looks good, but Google’s enshittification has won and it looks like no competent software developers are left. I would know, many of my friends work there.
Kiro, Cursor, Windsurf, etc#
All the “AI-first IDEs” kinda suck. They have opaque pricing, closed source prompts and systems, and sometimes just don’t work at all because they try to offer a free trial that would ruin them (looking at you Kiro).
I feel like a full-on IDE is not the right tool for using LLMs.
Closing thoughts on LLM products#
My perfect LLM tool would be a super lightweight client, with a terminal as the main interaction for LLM tools, but a webview on the side for the LLM to display information/navigate changes.
Adding all the interface of an IDE is just clutter for LLM-powered workflows, but staying 100% in the terminal is a bit too dry even for me.
Usage thoughts#
Language performance#
I want to take a second to highlight how good LLM agents are at writing Rust code.
Since the Rust compiler focuses so much on human readability, it is a perfect fit with LLM agents. The compiler output always points towards the right way to fix an issue.
On the opposite side, Python is a pretty poor fit despite the LLMs having so much training data on it. You need to setup strong typing all over your python code if you want LLMs to be actually helpful.
Best use cases#
LLMs have been helping me a lot in the following situations:
- Working with well established standards and implementing them
- For example, writing a Rust trait for Markdown serialization and deserialization with macros to generate update functions
- Writing integration tests
- LLMs are great at creating all the boilerplate and seeding data necessary for high quality testing
- Quickly bugfixing Sentry errors
- With the Sentry MCP I’m often able to just paste an issue URL to an agent and have it fix the issue if it was not too complicated
- Working with a new stack
- LLMs are very good at processing large amounts of documentation and implementing features based on it, but also passing that information back to you with recaps in markdown files
- Crafting small, private, replaceable pieces of software
- I made a CLI logs viewers and querier for my job, which is very useful but would have taken me a few days to write (~3k LoC)
Shortcomings#
LLM agents often add unnecessary complexity in their implementations of features, they create a lot of code duplication, and make you a worse developer.
Every time I tried using an LLM for core features of applications I develop at work, the implementations were questionable and I spent at least as much time rewriting the code than I would have spent writing it from scratch.
Regarding frontend, agents really struggled at making good, maintainable, DRY software. All models used magic numbers everywhere even when asked not to, keyboard interaction was poorly implemented, and some widgets took 5+ prompts to get right.
Flutter in particular was hard to get LLMs to write properly, despite it being a decently popular language. It is much better with React, but I don’t like the way LLM agents push you to just use the most popular language and framework, regardless of their quality.
Conclusion#
With agentic workflows and access to checks and tests outputs, LLMs have become very good at interacting with strongly typed languages.
They shine at working with well-tested backend applications, as the strong typing system and focus on tests makes it very hard for LLMs to get things wrong.
Regarding frontend, I’m more split. LLMs are great for creating simple interfaces based on widespread languages with widespread components libraries. But if you have a clear vision in mind, with complex keyboard interaction and custom components, it goes to shit fast.
If you feel like an LLM tool would be a good fit for your software development workflow, my current recommendation would be Github Copilot. It is good value for its price, and its high customizability lets you try things out to understand how things work.
But also, don’t feel like you’re forced to use an LLM to produce code. They are good tools for certain jobs, but they also still have many shortcomings that have not been fixed since their inception, and that doesn’t look to be solvable with the current approach. Because of their design, their knowledge will always be outdated, and they will always have a huge bias towards popular, widespread libraries.
I also sincerely hope that the hype dies down and that soon we will be able to run much lighter, focused LLMs. The current approach of “run the biggest possible LLM and make it do everything” is, imo, a horrendous idea. It burns much more energy than needed and sucks at most languages anyways.
That’s it for me. Don’t fall for the hype, but also, they are genuinely powerful tools sometimes.