As the lead member of our data analysis branch, I had to build our system from scratch and choose which technologies to use for every part of the stack. I think exploring the process I followed to create an efficient work environment can be helpful for people interested in data science and wanting to discover it with data they love!
Available data#
The first step when setting up your environment is to look at the kind of data you can gather. For League of Legends in particular, I am very lucky that there is a great API developed by Riot Games. The Riot API Discord was also a huge boon in setting up everything and finding help when I was struggling.
Here is a small sample of what you can get from the API:
- A list of the best players from each region
- The list of their last 100 games
- Info about each game
Here is the kind of data you can access about individual games:
- Game result and length, champion picks, runes used and items bought
- Game-end stats, like total damage dealt to champions, K/D/A, and gold
- Granular data in 1 minute slices, like CS or XP, as well as its difference with the player’s opponent in the same role
- Individual events, going from epic monster kill to ward usage
As you can see, there is a wealth of information at our disposal for ranked LoL games, begging to be put to good use.
While it is not as public facing as the ranked API, Riot also maintains an esports API with similar objects for esports games. I will come back to it later, as I first focused on setting up the structure by using the well-documented ranked API.
Constraints and data usage#
The data we get from Riot takes the form of multiple JSONs, with fields regularly changing to adapt to the game’s changes. The first step was storing this information myself to be able to query it more efficiently.
To do that, I needed a basic understanding of what I would do with the data. My understanding was that I would like to query specific data from games in my database, with the ability to filter them on any field. This might be an item, a champion, or a type of event. My database needed to be robust and fast.
So first, I did what any lazy person would do, and I explored NoSQL solutions. I gave MongoDB a shot, then tried DynamoDB, but they didn’t really seem satisfactory.
Despite my very limited SQL experience I realized it was the right tool for the job here, and I started by doing SQL Zoo’s tutorials to understand it better.
First solution#
Exploring the API and trying out NoSQL solutions already took me a few days, and I wanted to advance fast to serve results to the team as early as possible.
I therefore took a look at existing libraries from the community. I chose Python as my language because of its popularity in the data science field. I landed on PyCharm (free) as my IDE because I love IntelliJ, a similar IDE for Java.
This is when I discovered Cassiopeia, a community-built library including an SQL storage solution. This looked like a godsend, and I spent some time getting it to work before realizing the SQL storage wasn’t updated for the latest version of the API.

- My first database structure, mirroring Riot’s data
Thankfully, the person behind the SQL storage solution helped me a lot and told me what I needed to change for it to work. I got to it, and proudly added the Splyce logo to the list of contributors. Not gonna lie, it felt pretty good issuing a pull request after 4 years not doing any serious dev and on my first week using the language! But I feel sorry for the people who gave me a hand, because god was I bad…
On the hardware side of things, I decided to give Amazon Web Services a shot because I wanted to use it once and see what all the fuss was about. Thanks to their generous free tier, I could setup a Linux instance and a MySQL server for free. I might give a shot at Google’s Cloud solution in the future, as I am currently using TensorFlow for picks and bans analysis and could use their optimized hardware for it.
Starting to use the data#
At this point, I was well set up. I had my t2.micro instance running a parser calling match.load() and match.timeline.load() on every game I wanted to store. There were of course many issues with setting up the automation and making sure everything ran properly when adding thousands of matches an hour, but it was a good start.
Data was well organized in my database, and I started analyzing it. I wrote a patch 9.2 analysis report for my team, focusing on data not publicly available like overall rune and item win-rate. I used the underlying SQL alchemy implementation in Cassiopeia to directly query the database.
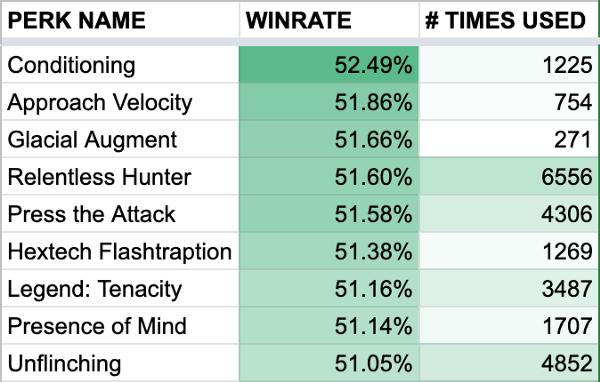
Looking at this data helped us gain a better understanding of the game. A rune only used by a subset of champions having a high win-rate means this group of champions is strong, and it influenced our picks and bans on stage. Spoiler alert: Aftershock is OP.
While using this data, I quickly realized mirroring Riot’s structure made it hard for me to do analysis. For example, items were in fields numbered from 0 to 6 and not their own table, which means that finding a specific item required me to query on 7 fields. This made for very heavy and inefficient SQL queries. And since the champion name was dissociated from a player’s stats, I was constantly joining tables with the same primary keys, which doesn’t make a lot of sense.
But I pushed onward, because I wanted to show my worth to the team and quickly deliver actionable data. A data scientist lives and dies by his credibility, and I think it’s important to not get lost in your infrastructure and force yourself to deliver usable information to your team regularly so they understand you’re not JUST getting angry at your computer all the time.
In particular, I spent some time time analyzing the marksmen items changes that came in patch 9.3, using a simple machine learning algorithm to find optimized marksmen builds. I won’t delve into much details here as it will be the focus of my second blog post, but let’s just say I was responsible for this Kobbe build.
Data reliability and Esports#
Very fast, I realized the API data wasn’t entirely reliable. The API flags players with a role, and it is wrong more than 30% of the time. Furthermore, the API uses this data to define CS and XP differentials, so those numbers were unreliable too. I quickly decided to not make use of this data in any of my reports, but kept thinking about ways to fix this crucial information. Spoiler alert, this will be blog post #4.
I was also tasked with including data about esports games in the database, as those are very important for coaches.
Unfortunately, the esports API is not gifted with the same kind of support than the ranked one. There is a pretty comprehensive unofficial documentation, but even with it it is still pretty hard to make use of it. I quickly gave up including any extra data for my first implementation, and just used my existing structure on a new database to save individual esports games.
Once again, providing quick results was key in cementing myself as a useful member of the team, but I already knew I would have to make a second pass on the data structure.
Current solution#
After finishing development of scripts to serve data to the team, I decided to re-start the whole development from scratch!
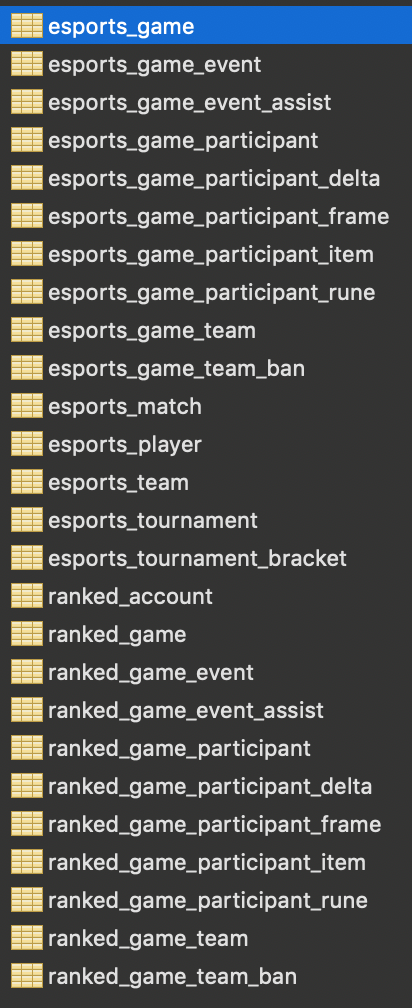
Current database structure
I really want to stress how important it was for me to start by prototyping and get a feel for my work flow to better understand the tools at my disposal. A month ago, I had no clue about anything Python or SQL related, but directly using those tools and forcing myself to provide results helped me improve fast.
This time, I started by choosing the right data structure for the information I was storing, then cast Riot’s JSON to it. Since ranked and esports games have very similar structure, I created abstract classes for common fields and methods. I also did some test driven development to make sure I knew where I was going.
I used SQL Alchemy to represent all the tables and their relationships for easy querying in Python. After creating a query with SQL Alchemy, it is painless to use it as a table with the pandas.read_sql() method.
Having full control over the process, I found a lot of optimizations for my parser and brought the speed from 30 games parsed a minute up to 180.
Conclusion#
Here are the tools I use currently:
- PyCharm as my IDE
- SQL as my database
- Sequel Pro as my MySQL database viewer
- SQL Alchemy as the way to retrieve data
- Pandas as my module to handle tables and perform data analysis
- AWS as my server provider (which involves basic Bash knowledge)
- Git as my version control system
If you are interested in video games and data science, just jump in! Learning those tools will come with using them to extract data that’s meaningful to you. There is no better teacher than experimentation.
On my side, my next blog posts will be focused on using machine learning to solve esports-related problems. I already had two very interesting projects, and those will be the theme of my next posts!